How To: Backup Cassandra on IKS
Backups in the kubernetes ecosystem is quite a bit different than traditional cassandra administration. At first glance it may seem like a complicated tasks, but i am going to expose just how easy it is. My prefered method to move towards a lengthy technical goal is to start with small working technical base, and slowly iterate towards what I need. In order to do backups on IKS I have to accomplish a few things:
- I need to enable backups in my cassandra cluster yaml
- I need to create a backup store (location) via CQL
- I need to create a backup configuration (timing) via CQL
First, the documentation here was a little confusing in how to enable backups. At first look the config is documented as:
config:
backup_service:
enabled: true
However I had to get information from internal resource that it is actually:
config:
cassandra-yaml:
backup_service:
enabled: true
With backups enabled in my cluster, I take the path of least resistance and create a backup store on local file system. I do not want to backup like this, but what i want to do is learn the backup process without fighting cloud storage access, authorization, and configuration. With the local file system method working I then tackle a backup store on IBMs cloud storage which is basically S3. The details of both of these are included in next sub sections.
How do I backup to File System?
The complete documenation for backups starts here.
![]() MAC users be warned, copy/pasting single quoted text often turns to ’quoted’ which will cause an error in cql.
MAC users be warned, copy/pasting single quoted text often turns to ’quoted’ which will cause an error in cql.
First I need a backup store:
CREATE BACKUP STORE store_name
USING 'FSBlobStore' WITH settings = {'path':'/tmp'};
Next I need to create a BACKUP CONFIGURATION which sets the timing for the backup using cron expression:
CREATE BACKUP CONFIGURATION config_name
OF keyspace
TO STORE backup_store
WITH frequency = 'cron expression'
AND enabled = true;
Before I can do that I need to create the keyspace to backup:
CREATE KEYSPACE IF NOT EXISTS demo WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'dc1' : 3 };
For my first test that BACKUP CONFIGURATION and frequency cron statement looks like:
CREATE BACKUP CONFIGURATION config_name
OF demo
TO STORE store_name
WITH frequency = '0 17 * * *'
AND enabled = true;
Now I am expecting to see some kind of backup at 1pm and I realize the pod time is probably different:
uptime
17:13:04 up 4:50, 0 users, load average: 0.22, 0.30, 0.66
![]() server time is off
server time is off
So I drop my first config with this command:
DROP BACKUP CONFIGURATION config_name;
And I redo it with the correct hour:
CREATE BACKUP CONFIGURATION config_name
OF demo
TO STORE store_name
WITH frequency = '0 18 * * *'
AND enabled = true;
Next I needed to create something to backup:
CREATE TABLE videos (
video_id timeuuid,
added_date timestamp,
description text,
title text,
user_id uuid,
PRIMARY KEY (video_id)
);
INSERT INTO videos (video_id,added_date,description,title,user_id) VALUES (now(),dateof(now()),'description',uuid());
And now I wait until the top of the hour, and validate the backup exists by logging into pod with bash:
kubectl -n cass-operator exec --stdin cluster1-dc1-default-sts-0 -- /bin/bash
Defaulting container name to cassandra.
Use 'kubectl describe pod/cluster1-dc1-default-sts-0 -n cass-operator' to see all of the containers in this pod.
uptime
17:51:07 up 5:28, 0 users, load average: 0.18, 0.45, 0.58
cd /tmp/dse
ls
dse.EJT1Kqc3C
ls
dse.EJT1Kqc3C
snapshots
cd /tmp/dse/snapshots
ls
15df1d07-c385-4b4c-a673-add1741ebe16
I now have a working foundation for moving forward with IBM Cloud Storage Backups.
How do I backup to S3 on IKS?
I need to follow the same process above just changing the store location from local file system to the cloud storage solution. This should be possible in GKE, AWK, and AKS. For IKS I should be able to use the S3Object storage class. According to IBM Cloud Object Storage Documentation:
“It uses IBM Cloud® Identity and Access Management for authentication and authorization, and supports a subset of the S3 API for easy migration of applications to IBM Cloud.”
I am following the steps here
CREATE BACKUP STORE store_name
USING 'S3BlobStore' WITH settings = {'bucket': 'amazon_bucket_name',
'region': 'amazon_region'};
![]() The sample needs to be expanded with settings found on this page here
The sample needs to be expanded with settings found on this page here
CREATE BACKUP STORE s3_store
USING 'S3BlobStore' WITH settings = {'bucket': 'my_s3_bucket',
'region': 'us-west-1',
'retention_time':'1w'
'retention_number' : 4};
I tried to create cloud object from terminal:
ibmcloud resource service-instance-create test_s3_store cloud-object-storage lite global
![]() No resource group targeted. Use ‘ibmcloud target -g RESOURCE_GROUP’ to target a resource group.
No resource group targeted. Use ‘ibmcloud target -g RESOURCE_GROUP’ to target a resource group.
This page allows create cloud object store in the UI:
https://cloud.ibm.com/catalog/services/cloud-object-storage
![]() Bucket name must be unique across entire IBM platform
Bucket name must be unique across entire IBM platform
{
"apikey": "qTRJYcPvz1T7FSevgjKR8fTw2qfeRs-GqUYb3UXDkYyP",
"endpoints": "https://control.cloud-object-storage.cloud.ibm.com/v2/endpoints",
"iam_apikey_description": "Auto-generated for key 44941bb8-4066-4ee0-9a30-9b3ee89595f9",
"iam_apikey_name": "Service credentials-1",
"iam_role_crn": "crn:v1:bluemix:public:iam::::serviceRole:Writer",
"iam_serviceid_crn": "crn:v1:bluemix:public:iam-identity::a/ea8f5c5aedc847438f0ad4c3e0381891::serviceid:ServiceId-56a8bfdf-1e88-4c48-8b04-46524ff8db3a",
"resource_instance_id": "crn:v1:bluemix:public:cloud-object-storage:global:a/ea8f5c5aedc847438f0ad4c3e0381891:2f9ad15b-d78c-44b4-ba98-ed7b58ee8382::"
}
![]() I had to look at some IBM Docs to try and decide what values map to S3 values.
I had to look at some IBM Docs to try and decide what values map to S3 values.
With all my info ready I can now create the cluster, get into cql, create my backup store, and backup configuration: https://docs.datastax.com/en/dse/6.8/dse-admin/datastax_enterprise/operations/opsBackupRestoreManaging.html
Connection error: ('Unable to connect to any servers', {'127.0.0.1:9042': AuthenticationFailed('Failed to authenticate to 127.0.0.1:9042: Error from server: code=0100 [Bad credentials] message="Failed to login. Please re-try."',)})
command terminated with exit code 1
![]() I ran into this issue yesterday too. You must allow some time for the cassandra cql service to be ready. It took maybe like 10 minutes from pod creation time for cql to respond.
I ran into this issue yesterday too. You must allow some time for the cassandra cql service to be ready. It took maybe like 10 minutes from pod creation time for cql to respond.
A second time after a pause:
Connected to cluster1 at 127.0.0.1:9042.
[cqlsh 6.8.0 | DSE 6.8.4 | CQL spec 3.4.5 | DSE protocol v2]
Use HELP for help.
cluster1-superuser@cqlsh>
Now I can execute my CQL:
CREATE KEYSPACE IF NOT EXISTS demo WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'dc1' : 3 };
use demo;
CREATE TABLE videos (
video_id timeuuid,
added_date timestamp,
description text,
title text,
user_id uuid,
PRIMARY KEY (video_id)
);
INSERT INTO videos (video_id,added_date,description,title,user_id) VALUES (now(),dateof(now()),'description','title',uuid());
![]() The function ‘dateof’ is deprecated. Use the function ‘toTimestamp’ instead.
The function ‘dateof’ is deprecated. Use the function ‘toTimestamp’ instead.
![]() I had some conflicts with cql (documented sample was missing some commas).
I had some conflicts with cql (documented sample was missing some commas).
Next I create my BACKUP STORE with the S3 settings I tried to infer above:
CREATE BACKUP STORE s3_store
USING 'S3BlobStore' WITH settings = {'bucket': 'mybucket-x12242020',
'endpoint': 'https://control.cloud-object-storage.cloud.ibm.com/v2/endpoints',
'access_key': 'qTRJYcPvz1T7FSevgjKR8fTw2qfeRs-GqUYb3UXDkYyP',
'secret_key': '2f9ad15b-d78c-44b4-ba98-ed7b58ee8382',
'retention_time':'1w',
'retention_number' : 4};
And then create a BACKUP CONFIGURATION:
CREATE BACKUP CONFIGURATION s3_backup
OF demo
TO STORE s3_store
WITH frequency = '0 15 * * *'
AND enabled = true;
I am now waiting until 10am (local time) to see if this worked or if there was an error. How am I going to see the error??? The VERIFY BACKUP STORE command will actually test the connection details:
cluster1-superuser@cqlsh> VERIFY BACKUP STORE s3_store;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Unable to write '64123c16-6d84-4ec4-ad3a-f0bc9c513687/d576d2ff-9c24-4fa1-be44-1c9d82189cea' blob due to service could not be contacted for a response"
![]() I need to do some more work with access & authorization to the bucket.
I need to do some more work with access & authorization to the bucket.
At this point I was able to jump ahead and find the solution by sharing the information I had learned. In doing so my team member exposed he knew a way to create the bucket credentials which would provide key and secret similar to S3.
When creating a Cloud Object Storage Service Credential click on Advanced and toggle “Include HMAC Credential”:
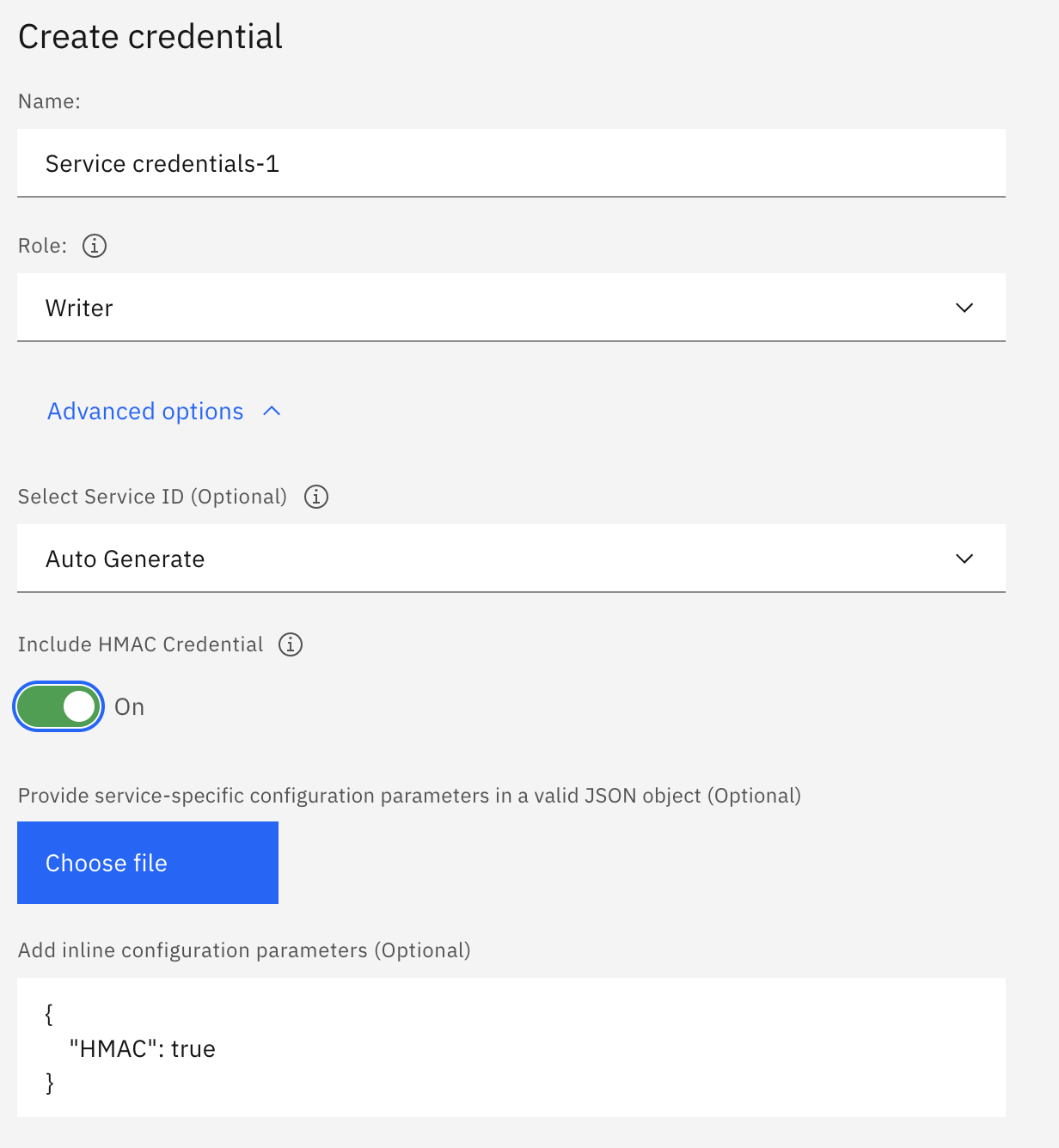
Now the service credential has what we need:
{
"apikey": "blO2SevY-YLoAaO6U1fWiqtZHAl3PhCMUlKlc2DxaQcB",
"cos_hmac_keys": {
"access_key_id": "af0ffc17c93d4e3a8730f746916fa5f3",
"secret_access_key": "1bd2ccaf7927abf2d6f35330ab15dee367349396950f54ac"
},
"endpoints": "https://control.cloud-object-storage.cloud.ibm.com/v2/endpoints",
"iam_apikey_description": "Auto-generated for key af0ffc17-c93d-4e3a-8730-f746916fa5f3",
"iam_apikey_name": "Service credentials-1",
"iam_role_crn": "crn:v1:bluemix:public:iam::::serviceRole:Writer",
"iam_serviceid_crn": "crn:v1:bluemix:public:iam-identity::a/ea8f5c5aedc847438f0ad4c3e0381891::serviceid:ServiceId-1e5e50b9-860f-41aa-b32e-4450feb8cc7b",
"resource_instance_id": "crn:v1:bluemix:public:cloud-object-storage:global:a/ea8f5c5aedc847438f0ad4c3e0381891:2f9ad15b-d78c-44b4-ba98-ed7b58ee8382::"
}
Using the access_key_id and secret_access_key values in the BACKUP STORE we are now able to successfully complete backing up Cassandra on IKS with IBM Cloud Storage.
CREATE BACKUP STORE s3_store
USING 'S3BlobStore' WITH settings = {'bucket': 'XXXXXXXXXX',
'endpoint': 'XXXXXXXX',
'access_key': 'XXXXXXXXXXXXXXXXXXXX',
'secret_key': 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'};
What’s Next?
Stay tuned to the Cass-Operator + IKS page as I complete exposing how to use the Datastax Cassandra Operator for Kubernetes on IBM Cloud IKS Platform.
How can I help you with Kubernetes?

Find me over on the DataStax Community to ask me any questions about Cassandra and Kubernetes. Also let’s chat if you have something kewl you did with Cassandra and Kubernetes and you want me to feature it in my blog. Look below or to the right for more ways to find me.